決定木分析とは?
やり方から活用例までわかりやすく解説!
SPSS Modelerを使ったデモ動画も用意
データ分析の予測手法のなかで、説明力が高く、予測モデル導入時によく使われてきた分析手法の一つが「決定木分析」になります。小さい木であれば機械学習を知らない人でも理解できるほど、解釈しやすい手法です。本コラムでは、決定木分析の基本からやり方、活用例までわかりやすく解説しました。AITで提供している統計解析ツール「IBM SPSS Modeler」を使った決定木分析のデモ動画もご用意しましたので、あわせてご覧ください。
1.決定木分析の活用例
決定木分析について詳しく解説する前に、まずは決定木分析がビジネスでどのように応用されているのか活用例を見ていきましょう。
決定木分析は、小売業やWebショップ、金融業など幅広い分野で活用されています。特定の商品の購入や契約などに関するスコア(確率)を予測するために、原因と考えられる情報をインプットして予測モデルを作成。将来の予測値を得て、購入率や契約率が上がるような施策を検出しています。
製造業においては、製造過程の条件をインプットとして故障や不良品発生の要因を特定しています。また、故障や不良品発生率の低い製品開発に活かしている例などもあります。
2.決定木分析とは
決定木分析(読み方:けっていぎぶんせき)とは、決定木とよばれる樹形図(ツリー構造)を使いデータを分析する手法です。英語では「Decision Tree Analytics」と記載します。
決定木分析では、全変数の可能な数の分岐点を試行しながら学習し、集中度の指標により2つのグループの応答の差が最大になるように分岐します。 実際に、保険の契約に関する樹形図を読み解きながら、決定木分析はどんなことをしているのか見ていきましょう。
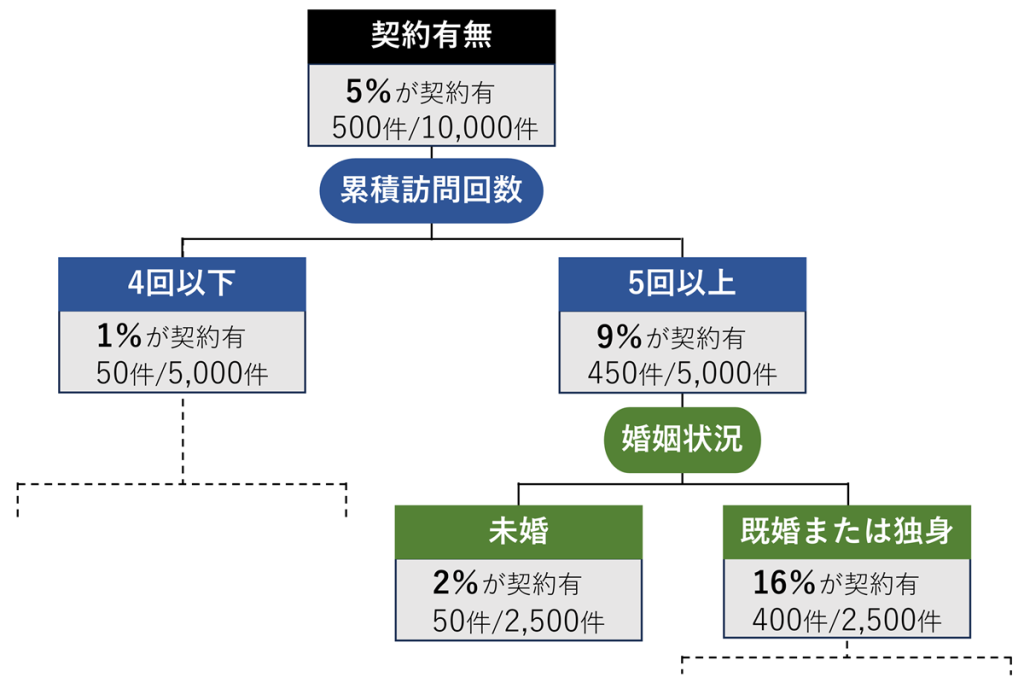
四角の部分を「ノード」と言い、一番初めのノード(契約有無)は「ルートノード」言われ、分析対象の統計量が表示されています。
10,000件訪問した内の、5%(500件)が契約に至りました。ルートノードを累積訪問回数「4回以下」と「5回以上」に分けると、累積訪問回数4回以下の場合は契約率1%(50件)、累積訪問回数5回以上は契約率9%(450件)となり、契約率が低いグループと高いグループに分けることができます。次に、契約率の高いグループ(累積訪問回数5回以上)のノードを「未婚」と「既婚または独身(離婚・死別)」で分けます。未婚の場合は契約率2%(50件)、既婚または独身の場合は契約率16%(400件)となり、こちらも契約率の高低で分けられました。
このように深い階層まで条件分岐を進めていくと、どんどん枝分かれしていき、根っ子(ルートノード)から木が逆さまに生えているような図になりますので、「樹形図」と呼ばれます。決定木分析を行うと、こういった樹形図が得られるので、決定木(ディシジョンツリー)の分析と言われています。
3.決定木分析の種類:C5.0、CHAID、CARTの違い
決定木分析には、具体的にはC5.0、CHAID、CARTなどのアルゴリズムがあります。予測対象(目的変数)の種類、分岐の数、分岐基準、欠損値処理などの違いで、下表のように比較できます。
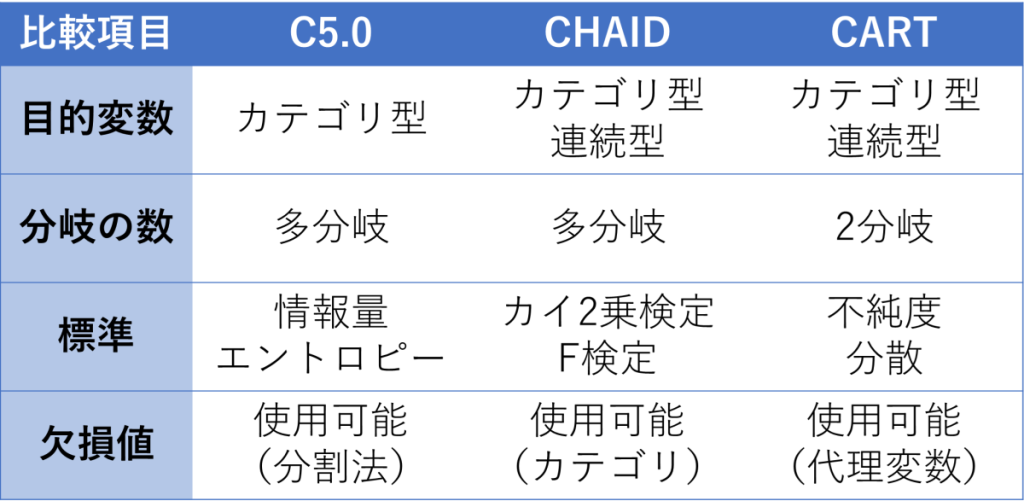
C5.0は、目的変数がカテゴリ型(質的変数)に限定されます。分岐の指標には「エントロピー(事象の不確かさ)」を使い、決定木分析ではエントロピーが小さくなるように分岐します。
CHAID(Chi-squared Automatic Interaction Detection)は、目的変数がカテゴリ型(質的変数)と連続型(量的変数)の両方で使え、C5.0と同様に多分岐の構造を持ちます。分岐の指標に使う「カイ2乗検定」は、分岐の差異に統計的な意味があるかを判定する指標で、目的変数が連続型の場合はF検定を用いることもあります。
CART(Classification And Regression Tree)は分岐の数が必ず2つになります。構造がシンプルなため理解しやすいというメリットがある一方で、データ量が多いと計算時間が長くなることもあります。
4.決定木分析のやり方・学習のステップ
決定木分析のやり方を解説します。決定木分析は、次の学習ステップに沿って行います。
【決定木分析の学習のステップ】
- 分岐基準
入力と定義された全ての変数(説明変数)内で、可能な分岐点を試行し、分岐前後の集中度改善が最大の点を検出 - 変数選択
上記の分岐後、全変数を比較し、集中度改善が最大となる変数で分岐 - 自動化
1、2を分岐後のノードで繰り返し、学習しながら全分岐を進める
例えば上記の樹形図の場合、ルートノードから出ている条件分岐が、「累積訪問回数:4回以下」と「累積訪問回数:5回以上」と表示されています。
実はこの条件分岐を導く裏では、かなりの計算が行われています。どのようにカテゴリ分けすると集中度が最も改善されるか、「累積訪問回数」だけでなく全ての変数で試算され、契約率が低い、契約率が高いというのが一番際立つ条件を算出しています。次に分岐後の全ての変数が比較され、最も集中度改善が大きかった「累積訪問回数:4回以下」と「累積訪問回数:5回以上」のセグメントに分けられるというわけです。
さらに「累積訪問回数:5回以上」のセグメントでは、再度、累積訪問回数を含めた全ての変数について、どのようにカテゴリ分けすると集中度が最も改善されるかが試算され、最も集中度改善が大きかった「婚姻状況:未婚」と「婚姻状況:既婚または独身(離婚・死別)」のセグメントに分けられます。分岐後の全てのセグメントで同様の変数分岐と比較が繰り返され、分岐変数を決定します。
以上のような決定木分析の計算を「IBM SPSS Modeler」で実施したのが次のデモ動画です。今回はCHAIDにて実施しました。決定木分析の理解がより深まると思いますので、あわせてご確認ください。
5.決定木分析の特徴
決定木分析の特徴として、次の2点が挙げられます。
- 非線形の関係をとらえられるので、線形の判別分析よりも高い予測精度が得られることが多い
- 外れ値もうまくモデルに取り込める
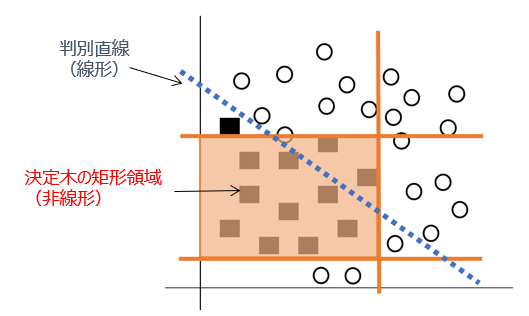
X軸は年齢、Y軸は収入とします。〇と■はお客さんで、〇は家を購入している人、■は家を購入していない人です。
決定木分析では、長方形(矩形領域)を形作っていき、ここの層の人たちは購入有、購入無と判別します。このように矩形領域を作ることで、非線形的な関係をとらえることができます。また、散布図中には年齢と収入が低い領域でも購入有を示す○がありますが、これらの外れ値(親から購入してもらったなど)もルールとして取り込めます。
これに対して線形判別分析では、散布図中に直線をひき、その直線上の一点から垂線を引いて、垂線より右上は購入有、左下は購入無と判別します。このように線形的な関係をとらえることはできますが、非線形な分布については、誤判別が多くなってしまいます。
参考:線形回帰分析とは?活用例から使い方、単回帰分析と重回帰分析の違いまで解説
6.まとめ
今回は、「決定木分析」の基礎について解説しました。「決定木分析」は様々なビジネス課題のヒントを得ることが期待できる分析手法です。
企業活動における分析対象は、企業内に蓄積されたデータのみならず、Webサイト上など社外の公開データ、さらにはSNSなどの外部データも含め、非常に多岐にわたるものとなっています。このため、社内外に蓄積された各種のデータを基に、透過的、そして一貫した形で予測分析を実現できる仕組みやサービスが求められています。 AITでは、分析プロジェクトの検討段階から、データ準備の支援、モデル開発、ビジネス活用、また人材育成までをトータルにご支援。お客様ご自身が継続的なデータ分析活動を推進できる組織、体制作りのお手伝いをします。お気軽にご相談ください。